
homebrew成功安装完毕后,在terminal输入:brew install tesseract 安装tesseract:

安装完毕后可用tesseract -v验证,顺便查看下版本:

从版本后面跟着的图片格式库可以看出tesseract支持jpeg、png和tiff为扩展名的图片。 接下来试着识别图片example_01上的英文字母:

在terminal上敲入命令tesseract 路径+文件名 stdout,将识别结果输出到屏幕上:
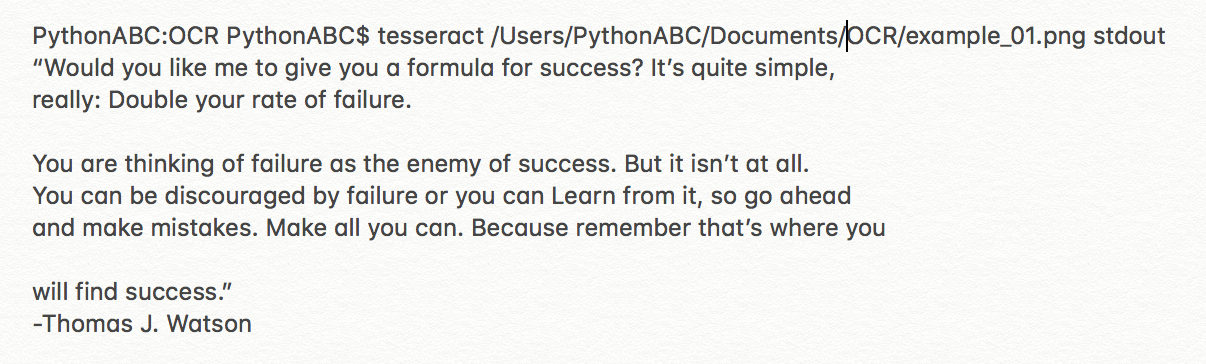
若要把识别结果保存到文档中,用文档名替换掉stdout:
tesseract /users/PythonABC/Documents/OCR/example_01.png output
则在当前文件夹(跟代码同一个文件夹)下,可以看到新生成的文件output.txt,内容是图片上识别出来的内容。
识别准确与否跟图片文字的背景有很大关系。这里用的背景是白色,字黑色的,是最利于识别的一种情况,实际上显然不可能这么完美。背景混杂(识别时的杂音)的文字识别起来难度系数增大,准确率下降,可以通过训练识别库来提高tesseract的识别率。如何训练这里不提及,有兴趣的朋友可以参看tesseract的技术文档,也可以下载资深人士训练好分享出来的识别库。事实上安装tesseract默认安装了英文字符训练库,帮助识别英文、英文标点符号和数字。
example_02.png如下:

现在来看tesseract能否识别出图片上的中文字,example_02在当前文件夹下:

识别不出来的原因是没有安装中文训练库,安装中文训练库的步骤如下:
1.下载中文训练字库
搜索引擎上搜索:tesseract Chinese training data,去tesseract的github的页面上下载中文简体字库:chi_sim.traineddata,当然如果还需要识别其他语言,可以把其他训练库一并下载了。
2.把下载的字库拷贝到tessdata目录下
terminal终端窗口上敲入命令brew list tesseract查看tessdata的位置:

最后一行就是tessdata的目录,把下载的目录拷贝到这个目录下,如果是 在Mac的terminal上可以用cp命令:

3.有些机器到此就可以调用中文训练库识别中文了,有些机器还需要设置环境变量TESSDATA_PREFIX为tessdata路径名,否则用加了指定语言参数的tesseract命令识别图片上的文字时会出现找不到训练库的错误

错误提示里有一句“Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.”,所以设置环境变量TESSDATA_PREFIX为tessdata的路径:
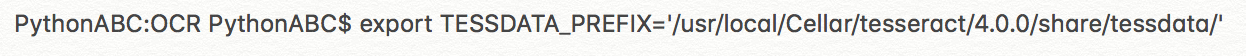
4.识别图片里的中文字符
命令的格式是:
tesseract路径+文件名输出-l 语言代码
默认识别的是英文字符,如果图片上有其他文字需要用语言参数-l说明。下载的语言训练库文件可能是jpn.traineddata(日语)、deu.traineddata(德语)、chi_sim.traineddata(简体中文)或sim_tra(繁体中文)等等,语言代码取文件名部分(jpn、deu、chi_sim或sim_tra)。
对example_02.png上的文字识别见图:

另外tesseract命令参数是讲究顺序和不可省略的的,比如写成:tesseract example_02.png -l chi_sim 是会出错的,如下图:

tesseract是有局限性的,对文字背景有要求,对像素有要求……需要特征抽取技术、机器学习技术和深度学习技术,用于识别的训练字库是可以被训练升级的,有兴趣的朋友可以自行研究
OCR识别图片和PDF上的文字之安装和使用Tesseract:
即将推出的Python ABC教程对PythonABC视频内容进行了梳理,修正了发现的错误、对代码做了些许优化、替换掉视频中的英文注释、替换掉国内不能访问的资源、添加windows上的设置和运行……敬请关注,谢谢