
PythonABC的教程基本完成,编辑刘大人建议每章结束后出几道思考题。这对我不是件容易的事儿,编程的题目最好既能串起知识点又能对解决实际问题有所帮助。年前跑去图书馆翻了几本python教材,希望一如既往奉行的“拿来主义”也能“拿来”好的思考题。大多数题目都太书生气,我若出题大概率也是这种风格,只有一本书上的题目还算接地气,揪出来了几道放进教程。
基础知识应付过去,python实例部分很吃力,实战经验太少,想不出实战的题目来。出到word这一张的题目时,正好在听许子东重读鲁迅和细读张爱玲,突发奇想何不出一道题目:在python-docx模块帮助下自动汇总作家的作品,生成图文并茂的word文档。想来应该不难,无非就是加段落加图片加表格,都有现成的方法函数。
题目出完后自己要做一做,看介绍的知识是不是足够用。结果做完后甚为不满,虽然可以完成既定任务,做出来的word文档却非常丑陋。对英文灵光的设置字体方法到中文字块这里完全不起作用,设置表格列宽的函数也不好用,添加的图片怎么不能居中?
好吧,还是先通过对鲁迅作品的处理来看我究竟是想让程序干什么吧(对于程序来说,一个作家的事儿整明白,十个作家还是一百个作家那都不叫事儿):
先建一个叫做鲁迅的文件夹,然后选鲁迅的几篇小说和小说中的人物放进一个txt文本(列表文件list.txt),内容是:
故乡 闰土
狂人日记 狂人
阿Q正传 阿Q
祝福 祥林嫂
孔乙己 孔乙己
伤逝 涓生、子君
药 夏瑜
然后按照列表找来作品的摘抄和跟作品相关的图片,放进鲁迅的文件夹里。鲁迅的文件夹长这样:
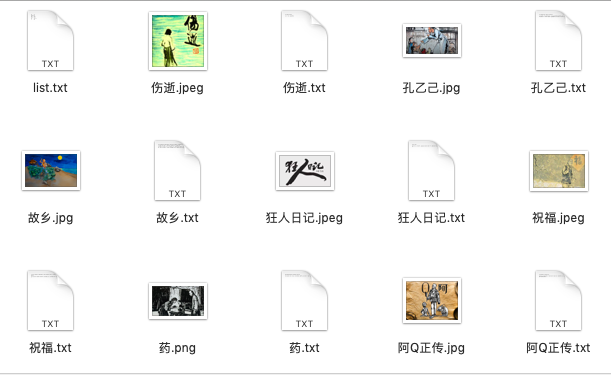
祝福.txt 长这样:
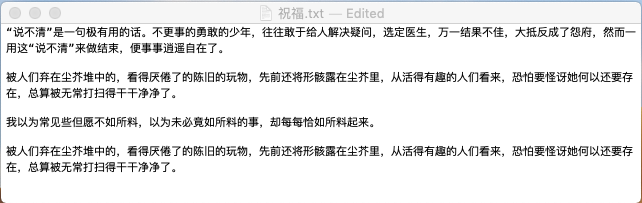
程序把这些原始素材组织起来自动编辑排版成如下word文档:




段落和表格里的中文字设置字体、图片居中和表格列宽的设定费了点周章。给出面向过程和面向对象两种实现方式,面向过程的代码如下:
# ---------------- 自动汇总材料生成Word文档(面向对象)---------------
from docx import Document # 操控word
from docx.enum.table import WD_TABLE_ALIGNMENT # 表格居中
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 标题居中
from docx.shared import Cm # 图片尺寸
from docx.oxml.ns import qn # 设置中文字体用
from pathlib import Path # 路径设置
def getElem(writer): # 从索引文件里获得作品、人物、文章内容、相关图片位置
currentFolder = Path('.').joinpath(writer) # 作家作品资料所在目录
listFile = currentFolder.joinpath('list.txt') # 作品资料索引
novelCharacter = {} # 作品-人物
novelQuote = {} # 作品-文章内容
novelPic = {} # 作品-图片
fileObj = listFile.open(encoding='utf-8') # 打开索引文件
dataLine = fileObj.readline() # 读出一行
while dataLine: # 读出内容为空,说明到了文章尾
novel, character = dataLine.split() # 从索引中获取作品和人物
for f in currentFolder.glob(novel + '.*'): # 从作品名搜作品内容和作品的相关图片
if f.suffix == '.txt': # 作品内容放在txt文档
quote = f
with quote.open(encoding='utf-8') as qObj: # 打开文章内容文件,按段落放进列表
paragraphs = qObj.read().split('\n')
novelQuote.setdefault(novel, paragraphs)
else: # 图片文件
pic = f
novelPic.setdefault(novel, str(pic)) # 作品和相关图像的位置字串
novelCharacter.setdefault(novel, character) # 作品和人物对应起来
dataLine = fileObj.readline()
return novelCharacter, novelQuote, novelPic # 返回三个构建word文档的字典变量
def setChineseFont(run, cFont): # 设置中文字体
font = run.font
font.name = cFont
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), cFont)
def createWord(author, nCharacter, nQuote, nPic): # 生成word文档
docObj = Document()
# 整个word文档的标题
docObj.add_heading(author+'小说及人物', level=0).alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 作品人物表格
table = docObj.add_table(rows = len(nCharacter.keys())+1, cols = 2, style = 'Light Grid Accent 1')
table.alignment = WD_TABLE_ALIGNMENT.CENTER # 表格居中
table.allow_autofit = False # 允许人工调节
for row in table.rows: # 设置表格每一列大小
row.cells[0].width = Cm(4)
row.cells[1].width = Cm(3)
table.rows[0].cells[0].text = '作品' # 表格头
table.rows[0].cells[1].text = '人物'
i = 1 # i是指向每个作品的指针
for k,v in nCharacter.items(): # 遍历小说-人物字典元素,k获得键值(作品),v获得值(人物)
# 加表格
table.rows[i].cells[0].text = k # 把作品和人物填进表格
table.rows[i].cells[1].text = v
i +=1 # 指向下一行
docObj.add_heading(k).alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 作品名做小标题
docObj.add_paragraph(nQuote[k][0]) # 写入文章第一段
docObj.add_picture(nPic[k], width=Cm(6)) # 加图片,设置图片尺寸
last_paragraph = docObj.paragraphs[-1] # 获得图片段落
last_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 图片居中
docObj.add_paragraph(nQuote[k][1:]) # 加上剩余的文字
for paragraph in docObj.paragraphs: # 设置所有段落文字字体
for run in paragraph.runs:
setChineseFont(run, 'KaiTi')
for row in table.rows: # 设置所有表格文字字体
for cell in row.cells:
for paragraph in cell.paragraphs:
for run in paragraph.runs:
setChineseFont(run, 'KaiTi')
return docObj
authorList = ['鲁迅'] # 只要作家材料准备完善就可以加入这个列表,自动生成排好版的文章
for author in authorList:
nCharacter, nQuote, nPic = getElem(author) # 获得组成word文档的原始材料
createWord(author, nCharacter, nQuote, nPic).save(author + '.docx') # 生成排好版的word文档
面向对象实现:
# ---------------- 自动汇总材料生成Word文档(面向对象)---------------
from docx import Document # 操控word
from docx.enum.table import WD_TABLE_ALIGNMENT # 表格居中
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 标题居中
from docx.shared import Cm # 图片尺寸
from docx.oxml.ns import qn # 设置中文字体用
from pathlib import Path # 路径设置
class Writer():
def __init__(self, name):
self.name = name
self.currentFolder = Path(name)
self.novelCharacter = {}
self.novelQuote = {}
self.novelPic = {}
self.getElem()
def getElem(self):
listFile = self.currentFolder.joinpath('list.txt')
fileObj = listFile.open(encoding='utf-8')
dataLine = fileObj.readline() # 读出一行
while dataLine: # 读出内容为空,说明到了文章尾
novel, character = dataLine.split() # 从索引中获取作品和人物
self.novelCharacter.setdefault(novel, character) # 作品和人物对应起来
for f in self.currentFolder.glob(novel + '.*'): # 从作品名搜作品内容和作品的相关图片
if f.suffix == '.txt': # 作品内容放在txt文档
with f.open(encoding='utf-8') as qObj: # 打开文章内容文件,按段落放进列表
# paragraphs = qObj.read().split('\n')
paragraphs = qObj.readlines()
self.novelQuote.setdefault(novel, paragraphs)
else: # 图片文件
self.novelPic.setdefault(novel, str(f)) # 作品和相关图像的位置字串
dataLine = fileObj.readline()
class novelCollection():
def __init__(self, authorObj):
self.master = authorObj
self.title = self.master.name + '小说及人物' # word文档的标题
self.filename = self.master.name + '.docx' # 保存的word文档的文件名
def launch(self):
docObj = Document()
# 整个word文档的标题
docObj.add_heading(self.title, level=0).alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# novelCollection.addTable(docObj, self.tableContent) # 加表格
self.addTable(docObj) # 加表格
for k, v in self.master.novelCharacter.items(): # 遍历小说-人物字典元素,k获得键值(作品),v获得值(人物)
docObj.add_heading(k).alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 作品名做小标题
docObj.add_paragraph(self.master.novelQuote[k][0]) # 写入文章第一段
self.addPicture(docObj, k) # 加入图片
# docObj.add_picture(self.pictures[k], width=Cm(6)).alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
docObj.add_paragraph(self.master.novelQuote[k][1:]) # 加上剩余的文字
for paragraph in docObj.paragraphs: # 设置所有段落文字字体
for run in paragraph.runs:
novelCollection.setChineseFont(run, 'KaiTi')
docObj.save(self.filename)
# 作品人物表格
def addTable(self, docObj):
# 添加表头,表格内容一行一行添加
table = docObj.add_table(rows=1, cols=2, style='Light Grid Accent 1')
table.alignment = WD_TABLE_ALIGNMENT.CENTER # 表格居中
table.rows[0].cells[0].text = '作品' # 表格头
table.rows[0].cells[1].text = '人物'
for k, v in self.master.novelCharacter.items(): # 遍历小说-人物字典元素,k获得键值(作品),v获得值(人物)
rowObj = table.add_row() # 表格加一行
rowObj.cells[0].text = k # 把作品和人物填进这一行
rowObj.cells[1].text = v
for row in table.rows: # 设置所有表格文字字体
for cell in row.cells:
for paragraph in cell.paragraphs:
for run in paragraph.runs:
novelCollection.setChineseFont(run, 'KaiTi')
# table.allow_autofit = False # 允许人工调节
for row in table.rows: # 设置表格每一列大小
row.cells[0].width = Cm(4)
row.cells[1].width = Cm(2)
def addPicture(self, docObj, k):
docObj.add_picture(self.master.novelPic[k], width=Cm(6)) # 加图片,设置图片尺寸
last_paragraph = docObj.paragraphs[-1] # 获得图片段落
last_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 图片居中
@staticmethod
def setChineseFont(run, cFont): # 设置中文字体
font = run.font
font.name = cFont
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), cFont)
authorList = ['鲁迅'] # 只要作家材料准备完善就可以加入这个列表,自动生成排好版的文章
for author in authorList:
writerObj = Writer(author)
novelCollection(writerObj).launch()视频解释如下: